1.2.4 – a new release is available
Hello, A new release is available ! In this update : – a new Sql Editor Tool – “Live Session”, “Wait Type”, “Update Dashboard” improved – and many bugs fixed. …
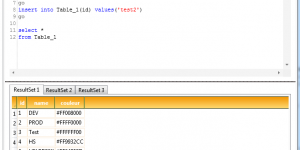
Hello, A new release is available ! In this update : – a new Sql Editor Tool – “Live Session”, “Wait Type”, “Update Dashboard” improved – and many bugs fixed. …