1.5.0 Custom queries
I didn’t post here for a while. Because of lockdown, I wasn’t motivated to work on the application. However, I received lot of messages asking me to add a query …
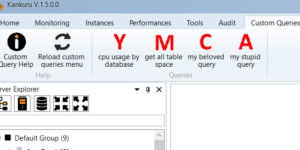
I didn’t post here for a while. Because of lockdown, I wasn’t motivated to work on the application. However, I received lot of messages asking me to add a query …
Le 6 juin 2020, j’ai présenté une session lors du PowerSaturday, dans laquelle j’ai parlé des tests unitaires en sql avec le framework tsqlt. La vidéo est enfin disponible Je …
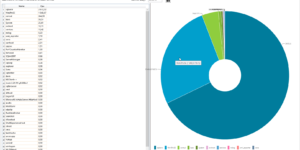
Hi all, long time without any new version of Kankuru. Lockdown didn’t help me to add new features but I finally found the courage to push this release 🙂 Live …

I received dozens of emails about this error : Zoltix also contacted the support on the forum http://kankuru.com/forum/topic/after-update-cannot-apply-value-null-to-property-login-value-cannot-be-null/ I just released the version 1.4.9.1 to fix the bug. Thank you …

It’s already the end of the year, a crazy year ! But it’s also time to release the last Kankuru version. I already teased it (in french) in this post. …
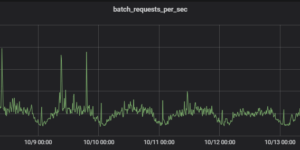
Bonjour tout le monde, j’écris ce post pour raconter un problème de lock rencontré à mon travail. C’était intéressant à investiguer donc autant le partager et à la fin je …
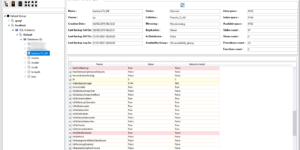
Hello all, summer is almost finished, it’s time to go back to work. So what’s new in this new version of Kankuru ? Database IdCard I’m sure you already used …

As a DBA, we’re often forced to use PowerShell scripts to automate database management. A script language on Windows is a great idea. Use the .Net framework is a great …
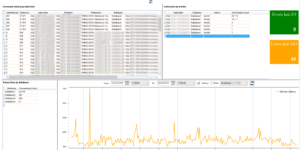
Hello, It was already 15 months ago… 15 months without any update of Kankuru ! Yes it was very long but here we go again, the new version is available. …

Le 1er juin, pour la première fois, j’ai posé le pied au Canada, à Montréal. J’y suis allé du 1er au 4, un aller-retour express, pour présenter une session lors …