SQLSaturday Montreal 2018
Après 1 mois de congés suite à la naissance de mon fils, je suis de retour au travail et j’ai eu la bonne nouvelle d’être sélectionné parmi les speakers du SQLSaturday …

Après 1 mois de congés suite à la naissance de mon fils, je suis de retour au travail et j’ai eu la bonne nouvelle d’être sélectionné parmi les speakers du SQLSaturday …
Only fews days before the birth of my son, I wanted to provide this new version in March. So what’s new ? Open in SSMS Sometimes, you’re in Kankuru and …
Hello, the 2nd version in 2018 is available. So what’s new in February ? Default trace Few weeks ago, a database was dropped on a UAT server. I restored it …

Microsoft organise le SQL Server on Linux tour. C’est un évènement international présent dans au moins 18 villes. Le 9 février, c’était au tour de Paris et j’ai eu la …
I’m still in time to wish you an happy new year. To celebrate 2018, I just released a new version. What’s new in this version ? New Icons Yes, I’m …
Hohoho, the new kankuru version is available. I think it will be my last commit in 2017. In this version, you’ll find new tools (Statistics, Live Io Profile), minor improvements …
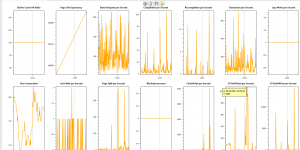
Few days before the Pass Summit, the new version is available. Instance Dashboard I added 4 new counters : transactions/second lazy Write/second disk Io Read/second disk IO Write/second The query …
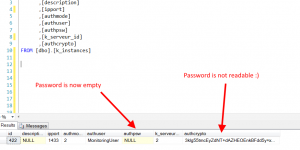
Only few days before holidays so I wanted to provide you the last Kankuru version. It’s summer in France but I added lot of new features 🙂 2 new Live …
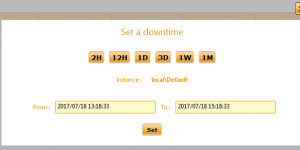
Hi, It’s summer, so it’s time to release the new version. Downtime Downtime is a new feature in the Dashboard. Sometimes, we don’t want to monitor a server for a …
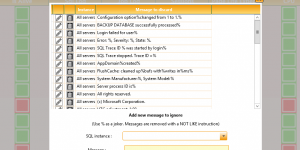
Hello Kankuru users, I just released a new version of Kankuru. Here’s the changelog. Discard GUI I wanted to do it for months and it’s done. The main dashboard check errorlogs, …