1.3.5 – Dashboard improvement with replication
Hello, I didn’t release Kankuru for a while but the version 1.3.5 is now available. This new version improve the dashboard with replication, the possibility to ignore messages and many other …

Hello, I didn’t release Kankuru for a while but the version 1.3.5 is now available. This new version improve the dashboard with replication, the possibility to ignore messages and many other …
Hello, it’s time for the December version : accessibility, readability, KMO migration, … New datagrid As you know, since I started migration to KMO, I also use a new datagrid …

Hi, The new version 1.3.3 is available with new features like the TempDB Dashboard. TempDB Dashboard I was at Pass summit in Seattle this year and I was in the …

Hello, a new minor version is available with new KMO integration. Snapshot backup type I’m sure you read all my posts so you should know I presented a session about KMO at …

Hello, I’m sure you already know PASS and the 24HOP but do you know its french vChapter ? Isabelle Van Campenhoudt and Christian Coté are the leader of this vChapter. …
Hello, a new version is available. So what’s new in this release ? Not just KMO 🙂 KMO I’m sure you know KMO, this is a project to open-source Kankuru queries. …
It’s time to update Kankuru, a new version is available with new features and KMO integration. With KMO (Kankuru Management Objects), an open source library, Kankuru will become more open …
4 years ago, I started to develop Kankuru. I had not enough time to create a beautiful website and since I like .net, I chose BlogEngine.net. It was very painful …
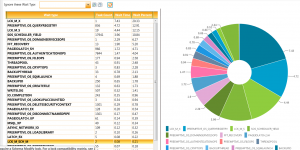
Live SP Profiler Parce qu’il n’est pas toujours facile de savoir à un instant T quelles sont les procédures stockées qui sont les plus coûteuses, j’ai ajouté ce nouvel outil …

Bonjour tout le monde, Mercredi 13 janvier, à partir de 18h30, nous organisons avec le GUSS une session chez Criteo (la société qui m’emploie). Nous parlerons de: L’organisation de l’équipe …