1.4.6 March version with SSMS integration and many other improvements
Only fews days before the birth of my son, I wanted to provide this new version in March. So what’s new ? Open in SSMS Sometimes, you’re in Kankuru and …
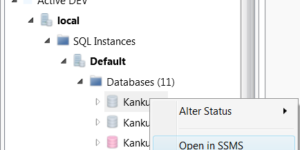
Only fews days before the birth of my son, I wanted to provide this new version in March. So what’s new ? Open in SSMS Sometimes, you’re in Kankuru and …
Hello, the 2nd version in 2018 is available. So what’s new in February ? Default trace Few weeks ago, a database was dropped on a UAT server. I restored it …

Microsoft organise le SQL Server on Linux tour. C’est un évènement international présent dans au moins 18 villes. Le 9 février, c’était au tour de Paris et j’ai eu la …
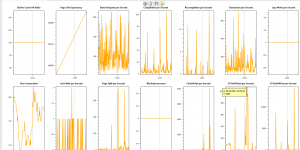
Few days before the Pass Summit, the new version is available. Instance Dashboard I added 4 new counters : transactions/second lazy Write/second disk Io Read/second disk IO Write/second The query …
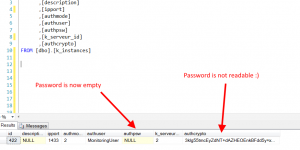
Only few days before holidays so I wanted to provide you the last Kankuru version. It’s summer in France but I added lot of new features 🙂 2 new Live …

Hello, I didn’t release Kankuru for a while but the version 1.3.5 is now available. This new version improve the dashboard with replication, the possibility to ignore messages and many other …
Hello, it’s time for the December version : accessibility, readability, KMO migration, … New datagrid As you know, since I started migration to KMO, I also use a new datagrid …

Hi, The new version 1.3.3 is available with new features like the TempDB Dashboard. TempDB Dashboard I was at Pass summit in Seattle this year and I was in the …

Hello, I’m sure you already know PASS and the 24HOP but do you know its french vChapter ? Isabelle Van Campenhoudt and Christian Coté are the leader of this vChapter. …
Hello, a new version is available. So what’s new in this release ? Not just KMO 🙂 KMO I’m sure you know KMO, this is a project to open-source Kankuru queries. …